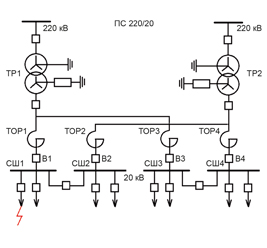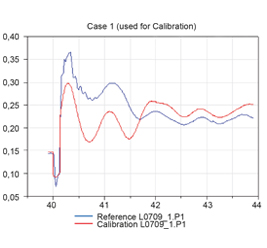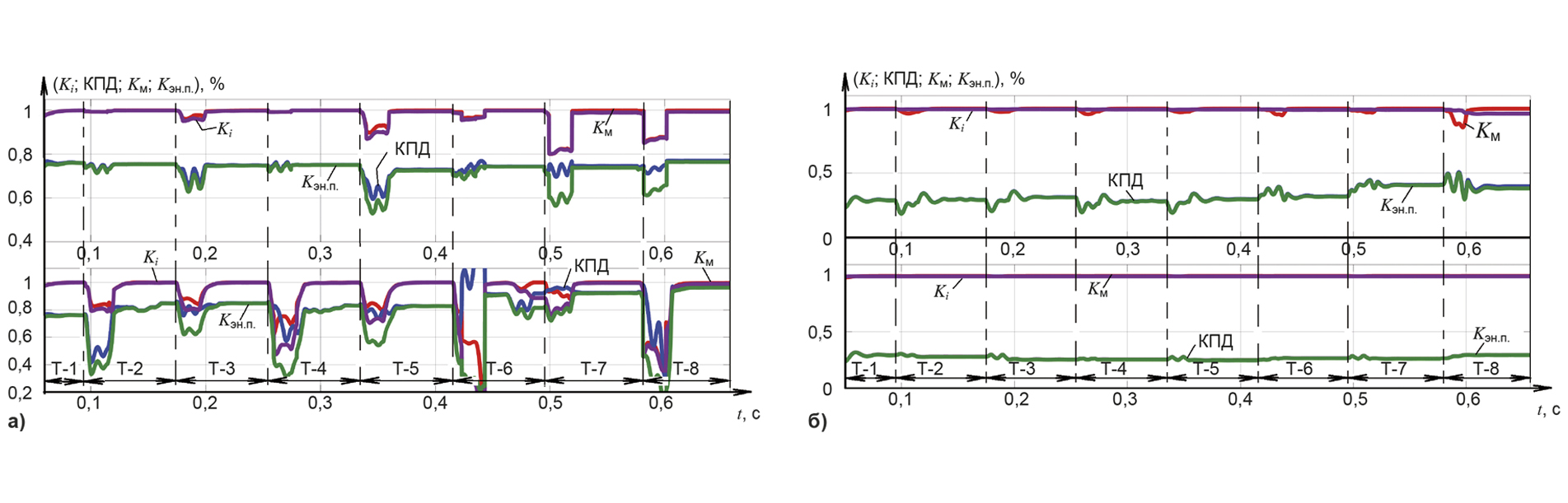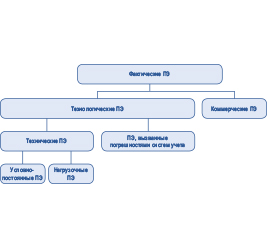
Оригинал статьи: Повышение эффективности почасового прогнозирования электропотребления с помощью моделей машинного обучения на примере Иркутской энергосистемы. Часть 2
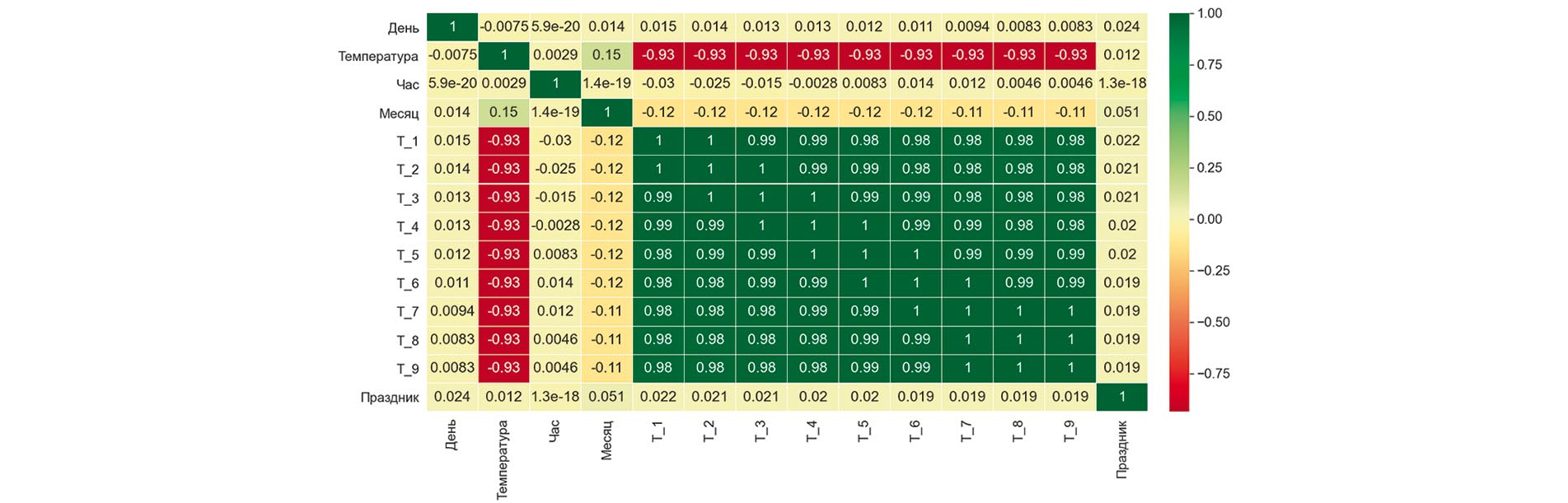
Решение задачи почасового прогнозирования электропотребления (ЭП) значительно усложняется при постоянном действии различных «нерегулярных» эффектов (метеофакторы, тяговая нагрузка, праздники, плохие данные и пр.), влияние которых в региональных диспетчерских управлениях (филиалах АО «СО ЕЭС») пытаются нивелировать фактически в ручном режиме, полагаясь на эмпирический опыт сотрудников. Такой подход часто приводит к увеличению ошибок суточного прогноза ЭП и, как следствие, дополнительным издержкам для АО «СО ЕЭС». В статье предлагается методология повышения эффективности почасового прогноза ЭП на базе моделей машинного обучения, позволяющая автоматизировать задачу коррекции моделей и повысить точность прогноза, прежде всего в условиях действия «нерегулярных» эффектов. Эффективность предложенного подхода продемонстрирована на примере реальных данных района Восточных электрических сетей Иркутской ЭЭС. Результаты прогноза на базе моделей машинного обучения сравниваются с данными корпоративного программного обеспечения, используемого АО «СО ЕЭС».