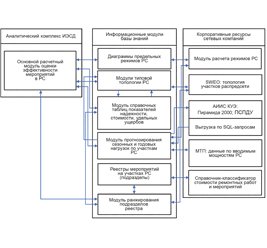
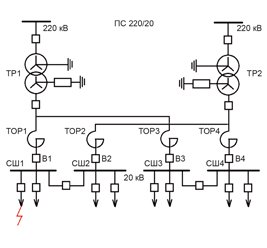
Оригинал статьи: Особенности подготовки и обработки данных для прогнозирования событий в распределительных электрических сетях
В 2006 году, выступая на конференции по маркетингу, математик Клайв Хамби высказал тезис, который сейчас определяет развитие не только отдельно взятых IT-фирм, но и целых отраслей: «Данные — это новая нефть. Как и нефть, они ценны, но не сами по себе, а благодаря продуктам на их основе. Данные должны быть обработаны, проанализированы для того, чтобы извлечь из них ценность, повысить рентабельность бизнеса». Что мы видим спустя полторы декады — большие объемы данных, или Big Data, становятся частью бизнес-модели в различных направлениях деятельности. Аналитики компании IDC прогнозируют, что к 2025 году во всем мире объем информации, который накоплен компаниями и потребителями, достигнет отметки в 163 зеттабайта. По сравнению с 2016 годом этот показатель вырастет в 10 раз.