Цифровизация топливно-энергетического комплекса привела к активному и практически повсеместному внедрению цифровых технологий и платформенных решений и в большинстве развитых стран даже вошла в число отдельных приоритетных национальных программ. Такая активная трансформация отрасли выявила новые проблемы, среди которых одними из основных стали проблемы непрерывного роста объемов данных и необходимость новых подходов к их обработке и анализу. Самым прогрессивным из этих подходов является применение искусственного интеллекта в энергетике.
Авторы данной статьи имеют достаточно большой опыт разработки и внедрения систем поддержки принятия решений на базе алгоритмов машинного обучения в задачах энергетики. В представленной статье они объединили весь свой практический опыт для анализа основных ошибок и последствий их влияния на результаты работы систем в электроэнергетической отрасли. В статье также описаны примеры интерпретации результатов и с точки зрения обработки данных, и, что еще важнее, с точки зрения их интерпретации для электроэнергетики.
Актуальность анализа ошибок при применении искусственного интеллекта в энергетике
Есть много публикаций, описывающих сами алгоритмы машинного обучения и принципы их работы и даже конкретные их отраслевые применения, в том числе для электроэнергетических задач. Но в Data Science именно обработанные данные, полученные в результате фильтрации и прочих преобразований, как и полученные в результате применения методов Data Mining, базы знаний представляют интеллектуальную собственность и чаще всего являются закрытой коммерческой информацией. В такой ситуации очевидно, что в каждом конкретном случае методы и подходы ИИ в энергетике, реализованные авторами исследования, практически невозможно повторить для верификации. В то же время особенности каждой конкретной задачи и возможности ее эффективного решения с помощью алгоритмов машинного обучения практически полностью зависят именно от использованных при решении задачи данных.
Сегодня машинное обучение общепризнанно является эффективным инструментом обработки данных, но вопрос его корректного применения именно разработчиками до сих пор является активно обсуждаемым. Сложность разработки систем искусственного интеллекта в сфере энергетики на системном уровне можно описать следующим образом: специалисты в области электроэнергетики не имеют необходимых знаний в области Data Science, а квалифицированные Data Science и IT-специалисты не представляют всей физики процессов генерации, передачи и потребления электрической энергии.
Отсюда появляются два типа глобальных ошибок. В первом случае — некорректной реализации математического аппарата и архитектуры программного обеспечения; во втором случае — некорректного формирования базы знаний и некорректной интерпретации полученных результатов. Поэтому эффективная реализация таких проектов возможна только совместной командой Data Science и IT-специалистов и специалистов-электроэнергетиков, каждый из которых дополнительно обладает хотя бы базовыми знаниями и в области Data Science, и в области электроэнергетики.
Возможные виды ошибок
Многие ученые в области электроэнергетики не обладают глубокими знаниями в Data Science и, что также очень важно, обычно не являются профессиональными программистами. Поэтому они считают, что реализация интеллектуальных систем заключается только в использовании конкретного алгоритма ИИ в электроэнергетике, что неверно. Если корректно использовать алгоритмы машинного обучения, то в результате формируется процесс, который объединяет в себе низкоуровневые детали и высокоуровневую структуру программного обеспечения.
Другими словами, какую бы задачу в области электроэнергетики вы не решали с помощью алгоритмов машинного обучения, в конечном счете вы создаете программное обеспечение. Это очень важно осознавать, так как для таких задач свойственны все соответствующие этапы и проблемы реализации программного обеспечения. Поэтому в данной статье возможные ошибки создания автоматизированных систем на базе искусственного интеллоекта условно разделены в зависимости от этапов реализации программного обеспечения в контексте электроэнергетических задач:
- ошибки на стадии сбора, анализа и подготовки данных;
- ошибки моделирования и тестирования
- ошибки промышленной эксплуатации.
Ошибки на стадии сбора, анализа и подготовки данных
По мнению авторов, ошибки, возникающие на этапе сбора, анализа и подготовки данных, имеют одни из самых тяжелых последствий для работы системы, так как именно входные параметры являются базой для систем искусственного интеллекта, и их неправильное понимание может привести к ошибкам при трансформации и интерпретации результатов. Если учесть, что преобразованные данные в одном этапе могут быть использованы как входные в другом, то становится понятно, что даже небольшая ошибка на раннем этапе может многократно усилиться и совершенно исказить результаты, привести или к результату с низкой точностью, или к совершенно некорректной интерпретации результата.
К основным этапам, на которых чаще всего совершают такие ошибки, можно отнести следующие ниже.
Выбор источников данных
Могут быть выбраны нерелевантные источники данных, так что данные могут быть изначально некорректными. Выбор источников данных целиком и полностью зависит от человека еще на этапе проектирования автоматизированной системы, поэтому такие системы должны разрабатываться совместно Data Science-специалистами и энергетиками. Такие ошибки могут привести к ложным корреляциям и зависимостям параметров, которых на самом деле может и вовсе не существовать. Например, когда для распознавания силовых трансформаторов 220 кВ используются данные о дефектах силовых трансформаторов 35 кВ. Цель алгоритмов машинного обучения – обобщение данных, поэтому машина ищет закономерности исключительно в тех данных, которые выбрал разработчик.
Важным аспектом в данной ситуации является изначальная корректность данных, здесь не идет речь про выбросы и частные ошибки в данных, а скорее о случаях плохих («отравленных») данных, когда, например, все в ту же исходную выборку по трансформаторам попадают данные с заведомо дефектных (например, еще с завода-изготовителя) трансформаторов, и в этой выборке число таких трансформаторов образует целый кластер. Также появление «отравленных» данных может быть умышленным, например, в результате кибератак, что также является вполне реальной проблемой Поэтому для автоматизированных систем, функционирующих на стратегических высоковольтных объектах, таких как станции и подстанции, нужно обеспечивать еще и безопасность передачи данных. Итогом ошибок на данном этапе при условии превалирования «отравленных» данных может быть полностью некорректная работа системы и неадекватное обобщение данных моделями.
Предобработка данных
Предобработка данных является неотъемлемым условием применения алгоритмов искусственного интеллекта в электроэнергетике и может включать в себя следующие процедуры:
- извлечение признаков;
- преобразование признаков;
- анализ взаимодействия признаков;
- заполнение пропусков;
- фильтрация и т.д.
И снова от разработчика на этапе проектирования системы зависит объем и очередность необходимых этапов обработки данных, а на этапах разработки и тестирования — валидация разработанных решений.
При выборе релевантных источников данных отсутствие их предобработки скорее приведет к низкой точности разработанной модели и низкой скорости работы такой системы, чем к систематическим ошибкам (при условии, что не стоит задачи работы системы в реальном времени). Например, в рамках авторских исследований было выявлено, что отсутствие процесса предобработки данных из релевантных источников в среднем снижает точность полученного результата для задачи прогнозирования генерации фотоэлектрических станций на 20-25%.
Принципы формирования выборок
Еще одним из важных этапов на стадии сбора, анализа и подготовки данных является выбор способа формирования и принципа деления данных на обучающую валидационную и тестовую выборки. Общепринято считать, что от объема обучающей выборки во многом зависит точность работы алгоритма искусственного интеллекта в энергетике. Такое утверждение не всегда корректно, так как большой объем обучающей выборки еще не гарантирует обеспечение баланса внутри нее. Например, для задачи классификации разбалансировка по классам (отсутствие данных определенных классов или кратное превалирование количества экземпляров одного класса над другим) может в конечном счете свести на нет всю работу системы, так как корректно обобщать алгоритм будет не способен. Аналогичные проблемы связаны и с формированием тестовой и валидационных выборок. Такие проблемы можно в общем случае решить либо с помощью нормализации, либо с помощью добавления или исключения обучающих данных и т.д.
Разбалансировка в обучающей и тестовой выборках практически всегда характерна для задачи распознавания дефектов высоковольтного оборудования вне зависимости от вида оборудования. Очевидно, что в генеральной совокупности в таких задачах будут преобладать параметры, характеризующие бездефектное состояние оборудования или, в худшем случае, определенные виды дефектов могут и вовсе отсутствовать. Если формировать обучающую и тестовую выборки в соответствии с общепринятым утверждением, что вероятность появления определенного вида дефекта в обучающей выборке равна вероятности появления данных дефектов в генеральной совокупности, то это приведет к тому, что система будет прекрасно распознавать бездефектное состояние и. скорее всего, редкие дефекты будут считать за «выбросы» в измерениях. Таким образом выбор процесса формирования и принципов деления данных на обучающие, тестовые и валидационные выборки должен быть отдельной задачей для разработчика интеллектуальных систем.
Ошибки моделирования и тестирования
Одной из фундаментальных ошибок применения алгоритмов машинного обучения для конкретной задачи электроэнергетики является отсутствие обоснования их использования. Несмотря на эффективность данного математического аппарата, разработчики систем искусственного интеллекта должны предварительно убедиться в реальной необходимости применения алгоритмов машинного обучения, а именно четко определить категорию задачи с точки зрения ее математической постановки, достаточности данных для ее корректной реализации, а также убедиться в неэффективности использования традиционных аналитических детерминированных подходов обработки и анализа данных.
Алгоритмы машинного обучения обычно стоит использовать в задачах с так называемыми большими данными (Big Data). Но есть алгоритмы машинного обучения, которые действительно могут быть эффективными и для небольшого объема данных, но для каждой конкретной задачи и каждого отдельного алгоритма необходимо дополнительно определять минимально требуемый и достаточный объем данных для реализации корректной обобщающей способности алгоритма.
Одной из главных проблем при моделировании систем искусственного интеллекта в энергетике с помощью алгоритмов машинного обучения является корректная постановка задачи машинного обучения и отнесения ее к одной из условно возможных категорий (наиболее распространенных в электроэнергетике):
- задаче регрессии — определению (прогнозированию) непрерывной зависимой переменной (или нескольких переменных) из ряда независимых переменных (например, прогнозированию генерации электрических станций или потребления электрической энергии);
- задаче классификации — разделению (или упорядочиванию) объектов по заранее известным классам (например, анализу технического состояния и определению принадлежности к одному из состояний электроэнергетического оборудования по показателям его функционирования);
- задаче кластеризации — разделению объектов на группы (кластеры) в зависимости от их схожести при условии, что их перечень кластеров заранее четко не задан и определяется в процессе работы алгоритмов, в том числе одной из подзадач кластеризации является определение наличия связи внутри кластеров (например, идентификация различных видов дефектов в высоковольтном оборудовании на основе различных данных технического диагностирования).
Задача регрессии, как и задача классификации являются задачами обучения с учителем и реализуются для заранее размеченных данных. Задача кластеризации является задачей обучения без учителя.
Каждая из категорий имеет особенности, области применения, преимущества и недостатки. Зачастую исследователи используют простой перебор методов в поиске решения для анализируемых задач, и чаще всего этот перебор основан на экспертном мнении и личном опыте разработчиков, и обоснование необходимости применения тех или иных алгоритмов выглядит не всегда убедительно.
Также стоит сразу же разделять задачи по необходимому времени ее решения и требуемому времени обучения модели машинного обучения:
- Оперативная задача, требующая большого (заранее определенного) объема высокого качества данных и малого времени обучения модели и предполагающая функционирование онлайн или в режиме, близком к темпу реального процесса. Например, задача оперативного планирования баланса мощности в энергосистеме с целью обеспечения баланса мощности (номинального уровня частоты), определения требуемого резерва мощности с учетом вероятности нарушения баланса мощности, где исходными данными являются нагрузка (оперативный прогноз потребления), выработка на выбранном интервале упреждения на электрических станциях, оперативный прогноз ВИЭ, электросетевые ограничения. Решение таких задач при их практическом отраслевом внедрении всегда сопряжены с необходимостью формирования инфраструктуры для их корректной реализации: необходимости гибкого хранилища данных и мощных распределенных вычислений.
- Среднесрочная задача, требующая достаточного объема данных для получения результата хорошей точности в разумное время например, задачи диагностики состояния оборудования с целью обнаружения развивающихся дефектов, где исходными данными являются данные о текущем техническом состоянии оборудования и его элементов. В данном случае речь не идет о системах онлайн-мониторинга.
- Долгосрочная задача, основные требования в которой предъявляются к увеличению точности при увеличении времени обучения в условиях ограниченности данных (либо небольшого объема данных, либо большого объема данных недостаточно высокого качества). Например, задача разработки схемы и программы развития энергосистемы с целью разработки мероприятий по обеспечению надежного электроснабжения субъектов, где к исходным относятся общие данные об энергосистеме, нагрузке, генерации. данные о предполагаемом развитии сети, изменении электропотребления, долгосрочные балансы мощности и электрической энергии и др. Обычно это так называемый класс систем-советчиков. или систем поддержки принятия решений.
Частные ошибки обычно являются следствием математической или программной неосведомленности (неопытности) разработчиков. Чаще всего ошибки связаны с процессами:
- выбора способа обучения модели (с учителем, без учителя, с подкреплением);
- выбора критериев качества модели (выбор метрики);
- анализа ошибок в результате работы алгоритмов и их интерпретация;
- адаптации или дообучения системы в случае появления новых объектов.
Примеры ошибок для реальной промышленной эксплуатации в задачах прогнозирования генерации
В реальной промышленной эксплуатации систем поддержки принятия решений на базе алгоритмов машинного обучения перечисленные выше ошибки могут встречаться как по отдельности, так и все вместе. В рамках данного раздела авторы приводят анализ возможных ошибок и их влияния на результаты работы системы на примере задачи прогнозирования генерации электрической энергии фотоэлектрической станции.
Актуальность решаемой задачи
Необходимость прогнозирования генерации возобновляемых источников энергии закреплена на государственном уровне, согласно приказу от 11 02 2019 № 91 «Об утверждении требований к прогнозированию потребления и формированию балансов электрической энергии и мощности энергосистемы на календарный год и периоды в пределах года»: «…Объем производства электрической энергии в прогнозном балансе электрической энергии энергосистемы должен определяться для ветровых и солнечных электростанций на основе помесячных данных о средней многолетней величине производства электрической энергии данными электростанциями за три последних года, а при отсутствии указанных данных (в том числе для строящихся электростанций) — в соответствии с предложениями собственников по формированию сводного прогнозного баланса… ». При этом на момент написания настоящей статьи авторам неизвестно универсальное надежное отраслевое решение задачи прогнозирования генерации фотоэлектрических станций, внедренное в технологическую деятельность основных субъектов энергетики.
В настоящее время при краткосрочном планировании электрических режимов с целью компенсации стохастического снижения выдачи мощности электростанциями на основе возобновляемых источников энергии увеличивается объем резервов активной мощности ЭЭС на суммарную величину генерации, заявленной собственниками таких генерирующих объектов, что фактически говорит о полном резервировании мощности возобновляемых источников генерации на традиционных тепловых электрических станциях.
С целью повышения эффективности краткосрочного планирования режимов в части соблюдения системных ограничений, размещения резервов активной мощности требуется создание инструментов прогнозирования генерации фотоэлектрических станций для краткосрочного (на сутки вперед) планирования. Кроме того, собственники фотоэлектрических станций также заинтересованы в развитии инструментов прогнозирования. В существующих условиях это позволит не только решать задачи выбора состава включенного генерирующего оборудования, планирования резервов мощности, но обеспечить эффективное планирование технического обслуживания и ремонтов основного генерирующего оборудования
Постановка задачи: разработка модели системы прогнозирования генерации фотоэлектрическими станциями на сутки вперед (краткосрочный прогноз).
Ошибка на этапе сбора данных
В редких случаях для решения задачи прогнозирования генерации фотоэлектрических станций, как и для любой другой задачи в реальной жизни, имеется готовый датасет — обработанный набор очищенных данных, пригодных для обработки алгоритмами машинного обучения.
Формирование такого набора данных — это не просто задача сбора данных, но и, что очень важно, ранжирование их источников по релевантности, где под релевантностью подразумевается степень отношения (соответствия) анализируемого объекта в датасете к вашей конкретной задаче.
Например, если исключить процесс ранжирования источников данных в задаче прогнозирования генерации фотоэлектрических станций, то в датасете могут оказаться данные, нерелевантные для решаемой задачи, например:
- данные со станций, расположенных в различных климатических зонах, или данные, собранные только в определенное время года, что и в том. и в другом случае приведет к неучету тренда и/или сезонной составляющей во временном ряде;
- данные фотоэлектрических станций, существенно отличающихся по типам солнечных панелей, по составу прочего оборудования, величине потерь в линиях и трансформаторах и т.д., что приведет к увеличению дисперсии прогнозируемой величины.
Таким образом нельзя случайным образом формировать исходный набор данных, ранжирование данных должно реализовываться с учетом различных факторов подтверждающих релевантность источников.
В качестве конкретного примера рассмотрим следующую ситуацию. Заказчик — компания-владелец ряда фотоэлектрических станций с условными названиями от А до К (11 объектов) ставит задачу по разработке системы прогнозирования графиков их генерации. Для наглядности на рисунке 1 представлено отображение полной выборки данных с этих станций в осях «месяц» — «географическая широта* (эти факторы выбраны, в первую очередь, для большей наглядности и простоты рисунка).
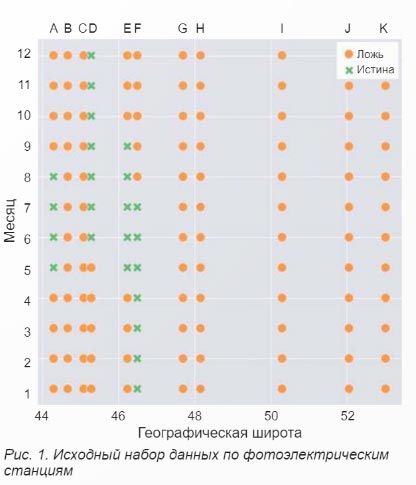
Крестиками отмечены данные, которые в данном примере попали в выборку при плохом планировании этапа сбора данных. Видно, что в выборке есть данные за каждый месяц, но при этом нет ни одной станции для которой в выборке были бы данные за все месяцы года. Охвачен определенный диапазон географических широт (климатических зон), но при этом нет данных по станциям В и С, входящим в этот диапазон. В результате на этапе построения, оценки и тестирования модели (принимаем что выборке разделена случайным образом на обучающую и тестовую) результаты на тестовой выборке могут оказаться достаточно хорошими для поставленной задачи, но в то же время модель окажется не пригодной для использования в жизни. Точность модели для всей системы показана на рисунке 2. в качестве критерия точности взят коэффициент детерминации R2.
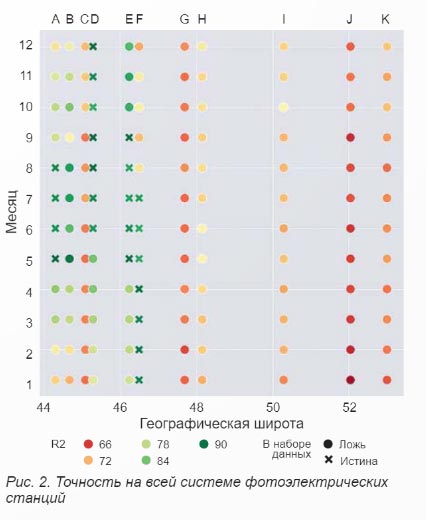
Снижение точности для станций G-K происходит по очевидным причинам — в выборке не было данных со станций, находящихся на этих широтах. Но из-за того, что временные интервалы (месяцы) были разными для разных станций, получилось так, что несмотря на наличие в выборке данных за весь год ни для одной из станций построенная модель не может применяться в течение всего года. Исключение — станция Е, поскольку в выборке были данные близких к ней станций D и F, охватывающие все месяцы года. Кроме того, результаты для станции С оказались неожиданно низкими, причем в любой из месяцев. Это объясняется особенностями самой станции С (электроэнергетическое оборудование, тип солнечных панелей и их соединение в единую систему производства электрической энергии).
В результате на этапе тестирования модели ее точность была высокой, при этом в тестовой выборке были данные по разным электростанциям, расположенным на разных широтах, данные по разным месяцам. Но на этапе эксплуатации оказывается, что модель не работает не только для фотоэлектрических станций на других широтах, в других климатических условиях, чего можно было ожидать, но не работает и для станций другого типа, расположенных в тех же широтах. И самое плохое, что модель может давать низкую точность в отдельные месяцы даже для тех самых станций, с которых были собраны исходные данные.
Поэтому на этапе планирования сбора данных необходимо:
- четко определять условия, в которых требуется, чтобы модель работала, и согласовывать их с заказчиком;
- собирать данные так, чтобы в выборке были представлены все требования и условия в достаточном для обучения и тестирования объеме и качестве;
- понимать, что должны быть представлены не только все условия, но и комбинации условий в случае их взаимного влияния.
В рассмотренном примере следовало бы начать со сбора данных за все месяцы и несколько лет одной фотоэлектрической станции, и только после успешной проверки работоспособности модели после ее внедрения и начала эксплуатации переходить к масштабированию модели (адаптации. дообучению, повторному обучению с нуля или даже построению совершенно новой модели) для других станций.
Ошибка на этапе предобработки данных
Отсутствие удаления выбросов (искажений данных). В предыдущей главе данной работы авторы описывали важность процесса предобработки данных. Ниже рассмотрен пример обучения регрессионной модели, прогнозирующей генерацию фотоэлектрических станций. На рисунке 3 показан фрагмент графика генерации до предобработки (содержит искажения, выделенные кружками) и после (искажения удалены). В общем случае ошибки в данных могут быть обусловлены:
- искажениями при измерениях и передаче данных;
- ошибками в программном коде конвертации и записи показаний измерительного прибора 8 файл;
- опечатками, которые сделаны из-за ручного копирования данных.
Искажения, показанные на рисунке 3, внесены в данные намеренно вручную для формирования данного примера.
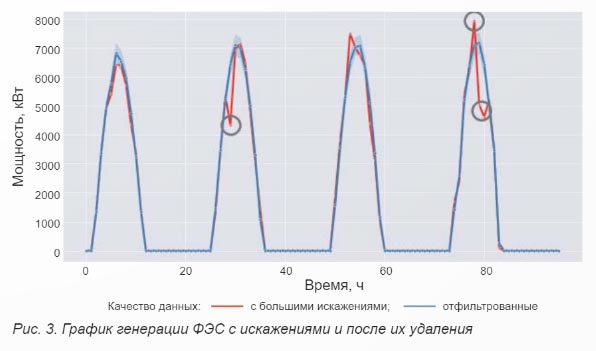
При обучении модель будет стремиться найти в исходных данных (график выработки, дата и время, метеорологические данные: температура, облачность, влажность, скорость ветра) зависимости. При этом искажения в данных могут искажать истинные зависимости и даже приводить к обнаружению ложных. Если применяются средства для борьбы с переобучением, то можно избежать формирования моделью ложных зависимостей, тем не менее искажения снизят точность, так как они исказят значения функции потерь при обучении и таким образом ухудшат сходимость процесса обучения.
В случае формирования ложных зависимостей модель в отдельные часы эксплуатации может давать прогноз с большими ошибками, как показано на рисунке 4. При этом такие ошибки будут для пользователя свидетельствами того, что 8 модели заложены неадекватные правила, что существенно снизит доверие к модели, которая и так является черным ящиком из-за применения алгоритмов машинного обучения.
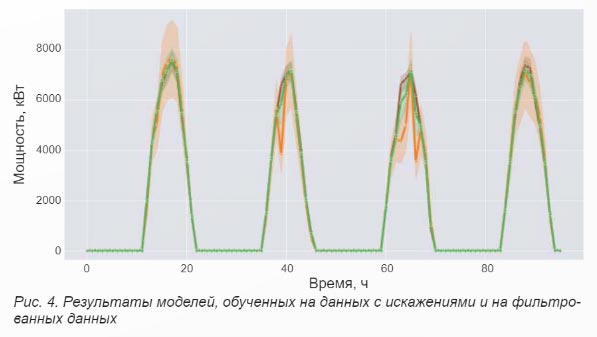
На рисунке 4:
- зеленая линия — настоящее значение генерации СЭС;
- коричневая — прогноз, полученный моделью, обученной на данных с исправлением больших искажений;
- оранжевая — прогноз, полученный моделью, обученной на данных с большими искажениями.
Полупрозрачные области показывают доверительный интервал. Ошибки из-за отсутствия предобработки исходных данных, как правило, снижают значения показателей точности, следовательно, расширяют доверительный интервал.
Чтобы избежать описанных негативных эффектов, необходимо:
- До начала обучения модели выполнить анализ данных с использованием статистических методов обнаружения выбросов и экспертного анализа результатов визуализации данных.
- На этапе оценки модели проводить отдельный анализ больших ошибок на валидационной выборке, поскольку такие ошибки могут быть связаны с искажениями входных данных или искажениями разметки данных (ground truth).
Ошибка выбора неподходящего показателя качества
От выбора показателя точности модели зависит и то, как будет проходить процесс ее обучения, и формирование заключения о полученных результатах. При этом как в задачах классификации, так и в задачах регрессии существует много различных показателей качества моделей. Выбор неподходящего показателя качества может ввести в заблуждение из-за того, что он не будет отражать качество модели по существу, с точки зрения эффективности ее эксплуатации. На рисунке 5 показан суточный график генерации ФЭС, прогноз некоторой модели и два графика показателя качества: модуль относительной ошибки |(у - у*) / у| и модуль абсолютного значения ошибки |у - у*|.
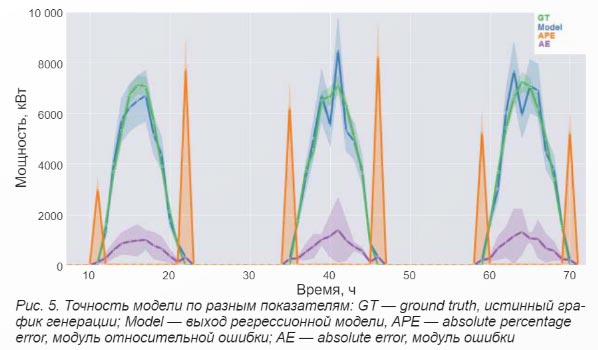
В данном примере, когда ошибка, по существу, большая, относительные значения ошибки низкие из-за большого значения истинной выработки. Зато в граничные часы (утренние и вечерние), совсем незначительная, по существу, ошибка приводит к огромным относительным ошибкам.
Если использовать относительную ошибку при обучении модели, то модель будет стремиться всегда давать нулевой выход, потому что даже небольшие отклонения в граничные часы будут давать очень большие значения относительной ошибки (более 100%).
Поэтому необходимо выбирать и интерпретировать показатели качества модели, исходя из того, для какой задачи будет использоваться модель, а также понимать, что ошибка означает по существу, не согласно математическим, а согласно физическим и экономическим критериям.
Ошибка выбора неподходящей по особенности задачи модели
Выбор модели и алгоритма машинного обучения, которые по своим особенностям не соответствуют задаче, приводит к недостижению требуемой точности. Такие ошибки менее опасны, чем рассмотренные выше ошибки, поскольку негативный эффект от них проявляется сразу же в процессе обучения модели, а не обнаруживается уже на этапе эксплуатации. Тем не менее попытки применения неподходящих моделей могут существенно увеличить затраты на разработку интеллектуальной системы, а в худшем случае привести к выводу о невозможности достичь требуемых показателей качества.
Для примера рассмотрено применение к той же задаче прогнозирования генерации ФЭС следующих моделей:
- полиномиальной регрессии;
- дерева решений;
- ансамбля деревьев, построенного алгоритмом градиентного бустинга.
На рисунке 6 приведен график дневной генерации ФЭС.
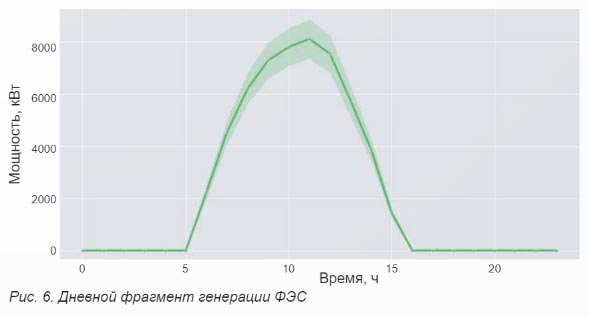
Очевидно, что в рассматриваемом примере модель должна уметь давать прогноз принципиально по-разному в диапазоне часов светового дня, а также в период после заката и до рассвета. Полиномиальная регрессионная модель не способна обучаться такой логике, поскольку является по своей природе непрерывной функцией. Дерево решений, наоборот, формирует кусочно-непрерывную функцию и легко обучается логике разделения рабочего и нерабочего интервалов, но при малой глубине не сможет точно прогнозировать генерацию из-за своей дискретности. Для решения задачи может эффективно быть применен ансамбль неглубоких деревьев решений.
Результаты моделей для данного фрагмента показаны на рисунке 7. Полиномиальная регрессия не может обучиться отсекать ночные часы и поэтому уходит на них в минус. Неглубокое дерево решений дает слишком ступенчатый выход, так как не может достаточно точно описать график из-за своей дискретности.
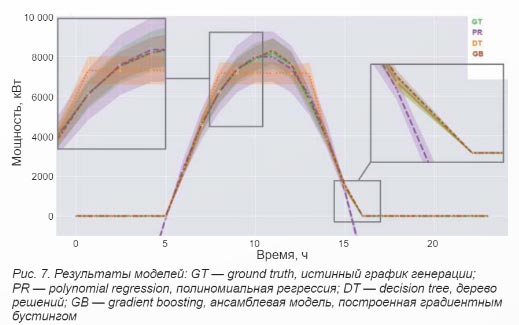
Чтобы избежать ошибочного выбора неподходящей модели и алгоритма обучения, следует:
- понимать особенности задачи и характер изменений целевой величины;
- понимать математическую природу моделей и принципы работы алгоритмов их обучения;
- проводить анализ не только показателей качества модели, но и сопоставление ее выхода с требуемым.
Заключение
Рассмотренные примеры ошибок обосновывают абсолютную необходимость тесного взаимодействия специалистов в Data Science со специалистами в электроэнергетике на всех этапах разработки систем искусственного интеллекта в электроэнергетике. На каждом этапе необходимо как полное понимание специфики решаемой задачи и рассматриваемого объекта, так и глубокое понимание принципов работы математических моделей, алгоритмов и статистических показателей. Недостаток как первого, так и второго с высокой вероятностью приведут к увеличению затрат на создание интеллектуальной системы или снижению показателей качества работы модели на этапе ее эксплуатации.
В данной статье были продемонстрированы на реальных примерах в различных электроэнергетических задачах возможные ошибки при разработке автоматизированных систем на базе машинного обучения и выявлены основные этапы, на которых имеет смысл дополнительно проверять корректность использования алгоритмов искусственного интеллекта (на стадии сбора анализа и подготовки данных, на стадии моделирования и тестирования и на стадии промышленной эксплуатации) Также в статье были представлены рекомендации для выявления таких ошибок и их интерпретация на каждом из этапов.
Оригинал статьи: Анализ ошибок применения алгоритмов машинного обучения в задачах электроэнергетики
Сегодня цифровизация топливно-энергетического комплекса во всем мире привела к активному и практически повсеместному внедрению цифровых технологий и платформенных решений и в большинстве развитых стран даже вошла в число отдельных приоритетных национальных программ. Такая активная трансформация отрасли выявила новые проблемы, среди которых одними из основных стали проблемы непрерывного роста объемов данных и необходимость новых подходов к их обработке и анализу. Авторы данной статьи имеют достаточно большой опыт разработки и внедрения систем поддержки принятия решений на базе алгоритмов машинного обучения в различных задачах электроэнергетики и в представленной статье попытались агрегировать весь свой практический опыт для анализа основных ошибок и последствий их влияния на результаты работы таких систем в электроэнергетической отрасли. В статье также описаны примеры интерпретации результатов и с точки зрения обработки данных, и, что еще важнее, с точки зрения их интерпретации для электроэнергетики.